Inapoi
Inainte
Cuprins
Why virtual functions?
At this point you may have a question:
“If this technique is so important, and if it makes the
‘right’ function call all the time, why is it an option? Why do I
even need to know about it?”
This is a good question, and the answer
is part of the fundamental philosophy of C++: “Because it’s not
quite as efficient.” You
can see from the previous assembly-language output that instead of one simple
CALL to an absolute address, there are two – more sophisticated –
assembly instructions required to set up the virtual function call. This
requires both code space and execution time.
Some object-oriented languages have taken
the approach that late binding is so intrinsic to object-oriented programming
that it should always take place, that it should not be an option, and the user
shouldn’t have to know about it. This is a design decision when creating a
language, and that particular path is appropriate for many
languages.[56]
However, C++ comes from the C heritage, where efficiency is critical. After all,
C was created to replace assembly language for the implementation of an
operating system (thereby rendering that operating system – Unix –
far more portable than its predecessors). One of the main reasons for the
invention of C++ was to make C programmers more
efficient.[57] And
the first question asked when C programmers encounter C++ is, “What kind
of size and speed impact will I get?” If the answer were,
“Everything’s great except for function calls when you’ll
always have a little extra overhead,” many people would stick with C
rather than make the change to C++. In addition, inline functions
would not be possible, because
virtual functions must have an address to put into the VTABLE. So the virtual
function is an option, and the language defaults to nonvirtual, which is
the fastest configuration. Stroustrup stated that his guideline was, “If
you don’t use it, you don’t pay for it.”
Thus, the
virtual keyword is
provided for efficiency tuning. When designing your classes, however, you
shouldn’t be worrying about efficiency tuning. If you’re going to
use polymorphism, use virtual functions everywhere. You only need to look for
functions that can be made non-virtual when searching for ways to speed up your
code (and there are usually much bigger gains to be had in other areas – a
good profiler will do a better job of finding bottlenecks than you will by
making guesses).
Anecdotal evidence suggests that the size
and speed impacts of going to C++ are within 10 percent of the size and speed of
C, and often much closer to the same. The reason you might get better size and
speed efficiency is because you may design a C++ program in a smaller, faster
way than you would using
C.
Abstract base classes and pure virtual
functions
Often in a design, you want the base
class to present only an interface for its derived classes. That is, you
don’t want anyone to actually create an object of the base class, only to
upcast to it so that its interface can be used. This is accomplished by making
that class abstract, which happens if you give it at least one pure
virtual function. You can recognize a pure virtual function because it uses
the virtual keyword and is followed by = 0. If anyone tries to
make an object of an abstract class, the compiler prevents them. This is a tool
that allows you to enforce a particular design.
When an abstract class is inherited, all
pure virtual functions must be implemented, or the inherited class becomes
abstract as well. Creating a pure virtual function allows you to put a member
function in an interface without being forced to provide a possibly meaningless
body of code for that member function. At the same time, a pure virtual function
forces inherited classes to provide a definition for it.
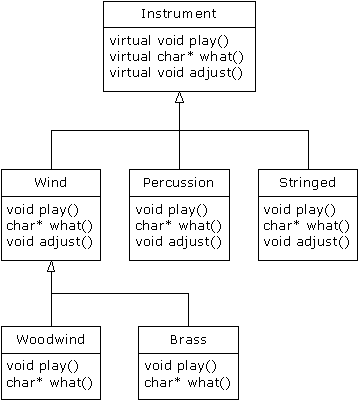
In all of the instrument examples, the
functions in the base class Instrument were always “dummy”
functions. If these functions are ever called, something is wrong. That’s
because the intent of Instrument is to create a common interface for all
of the classes derived from it.
The only reason to establish the common
interface is so it can be
expressed differently for each different subtype. It creates a basic form that
determines what’s in common with all of the derived classes –
nothing else. So Instrument is an appropriate candidate to be an abstract
class. You create an abstract class when you only want to manipulate a set of
classes through a common interface, but the common interface doesn’t need
to have an implementation (or at least, a full implementation).
If you have a concept like Instrument
that works as an abstract class, objects of that class almost always have no
meaning. That is, Instrument is meant to express only the interface, and
not a particular implementation, so creating an object that is only an
Instrument makes no sense, and you’ll probably want to prevent the
user from doing it. This can be accomplished by making all the virtual functions
in Instrument print error messages, but that delays the appearance of the
error information until runtime and it requires reliable exhaustive testing on
the part of the user. It is much better to catch the problem at compile
time.
Here is the syntax used for a pure
virtual declaration:
virtual void f() = 0;
By doing this, you tell the compiler to
reserve a slot for a function in the VTABLE, but not to
put an address in that particular slot. Even if only one function in a class is
declared as pure virtual, the VTABLE is incomplete.
If the VTABLE for a class is incomplete,
what is the compiler supposed to do when someone tries to make an object of that
class? It cannot safely create an object of an abstract class, so you get an
error message from the compiler. Thus, the compiler guarantees the purity of the
abstract class. By making a class abstract, you ensure that the client
programmer cannot misuse it.
Here’s Instrument4.cpp
modified to use pure virtual functions. Because the class has nothing but pure
virtual functions, we call it a pure abstract class:
//: C15:Instrument5.cpp
// Pure abstract base classes
#include <iostream>
using namespace std;
enum note { middleC, Csharp, Cflat }; // Etc.
class Instrument {
public:
// Pure virtual functions:
virtual void play(note) const = 0;
virtual char* what() const = 0;
// Assume this will modify the object:
virtual void adjust(int) = 0;
};
// Rest of the file is the same ...
class Wind : public Instrument {
public:
void play(note) const {
cout << "Wind::play" << endl;
}
char* what() const { return "Wind"; }
void adjust(int) {}
};
class Percussion : public Instrument {
public:
void play(note) const {
cout << "Percussion::play" << endl;
}
char* what() const { return "Percussion"; }
void adjust(int) {}
};
class Stringed : public Instrument {
public:
void play(note) const {
cout << "Stringed::play" << endl;
}
char* what() const { return "Stringed"; }
void adjust(int) {}
};
class Brass : public Wind {
public:
void play(note) const {
cout << "Brass::play" << endl;
}
char* what() const { return "Brass"; }
};
class Woodwind : public Wind {
public:
void play(note) const {
cout << "Woodwind::play" << endl;
}
char* what() const { return "Woodwind"; }
};
// Identical function from before:
void tune(Instrument& i) {
// ...
i.play(middleC);
}
// New function:
void f(Instrument& i) { i.adjust(1); }
int main() {
Wind flute;
Percussion drum;
Stringed violin;
Brass flugelhorn;
Woodwind recorder;
tune(flute);
tune(drum);
tune(violin);
tune(flugelhorn);
tune(recorder);
f(flugelhorn);
} ///:~
Pure virtual functions are helpful
because they make explicit the abstractness of a class and tell both the user
and the compiler how it was intended to be used.
Note that pure virtual functions prevent
an abstract class from being passed into a function by value. Thus, it is
also a way to prevent object slicing (which will be described
shortly). By making a class abstract, you can ensure
that a pointer or reference is always used during upcasting to that
class.
Just because one pure virtual function
prevents the VTABLE from being completed doesn’t mean that you don’t
want function bodies for some of the others. Often you will want to call a
base-class version of a function, even if it is virtual. It’s always a
good idea to put common code as close as possible to the root of your hierarchy.
Not only does this save code space, it allows easy propagation of
changes.
Pure virtual
definitions
It’s possible to provide a
definition for a pure virtual function in the base class. You’re still
telling the compiler not to allow objects of that abstract base class, and the
pure virtual functions must still be defined in derived classes in order to
create objects. However, there may be a common piece of code that you want some
or all of the derived class definitions to call rather than duplicating that
code in every function.
Here’s what a pure virtual
definition looks like:
//: C15:PureVirtualDefinitions.cpp
// Pure virtual base definitions
#include <iostream>
using namespace std;
class Pet {
public:
virtual void speak() const = 0;
virtual void eat() const = 0;
// Inline pure virtual definitions illegal:
//! virtual void sleep() const = 0 {}
};
// OK, not defined inline
void Pet::eat() const {
cout << "Pet::eat()" << endl;
}
void Pet::speak() const {
cout << "Pet::speak()" << endl;
}
class Dog : public Pet {
public:
// Use the common Pet code:
void speak() const { Pet::speak(); }
void eat() const { Pet::eat(); }
};
int main() {
Dog simba; // Richard's dog
simba.speak();
simba.eat();
} ///:~
The slot in the Pet VTABLE is
still empty, but there happens to be a function by that name that you can call
in the derived class.
The other benefit to this feature is that
it allows you to change from an ordinary virtual to a pure virtual without
disturbing the existing code. (This is a way for you to locate classes that
don’t override that virtual
function.)
Inheritance and the
VTABLE
You can imagine what happens when you
perform inheritance and override some of the virtual functions. The compiler
creates a new VTABLE for your new class, and it inserts your new function
addresses using the base-class function addresses for any virtual functions you
don’t override. One way or another, for every object that can be created
(that is, its class has no pure virtuals) there’s always a full set of
function addresses in the VTABLE, so you’ll never be able to make a call
to an address that isn’t there (which would be
disastrous).
But what happens when you inherit and add
new virtual functions in the derived
class?
Here’s a simple example:
//: C15:AddingVirtuals.cpp
// Adding virtuals in derivation
#include <iostream>
#include <string>
using namespace std;
class Pet {
string pname;
public:
Pet(const string& petName) : pname(petName) {}
virtual string name() const { return pname; }
virtual string speak() const { return ""; }
};
class Dog : public Pet {
string name;
public:
Dog(const string& petName) : Pet(petName) {}
// New virtual function in the Dog class:
virtual string sit() const {
return Pet::name() + " sits";
}
string speak() const { // Override
return Pet::name() + " says 'Bark!'";
}
};
int main() {
Pet* p[] = {new Pet("generic"),new Dog("bob")};
cout << "p[0]->speak() = "
<< p[0]->speak() << endl;
cout << "p[1]->speak() = "
<< p[1]->speak() << endl;
//! cout << "p[1]->sit() = "
//! << p[1]->sit() << endl; // Illegal
} ///:~
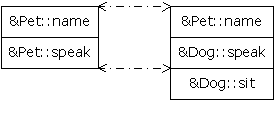
The class Pet contains a two
virtual functions: speak( ) and name( ). Dog adds
a third virtual function called sit( ), as well as overriding the
meaning of speak( ). A diagram will help you visualize what’s
happening. Here are the VTABLEs created by the compiler
for Pet and Dog:
Notice that the compiler maps the
location of the speak( ) address into exactly the same spot in the
Dog VTABLE as it is in the Pet VTABLE. Similarly, if a class
Pug is inherited from Dog, its version of sit( ) would
be placed in its VTABLE in exactly the same spot as it is in Dog. This is
because (as you saw with the assembly-language example) the compiler generates
code that uses a simple numerical offset into the VTABLE to select the virtual
function. Regardless of the specific subtype the object belongs to, its VTABLE
is laid out the same way, so calls to the virtual functions will always be made
the same way.
In this case, however, the compiler is
working only with a pointer to a base-class object. The base class has only the
speak( ) and name( ) functions, so those is the only
functions the compiler will allow you to call. How could it possibly know that
you are working with a Dog object, if it has only a pointer to a
base-class object? That pointer might point to some other type, which
doesn’t have a sit( ) function. It may or may not have some
other function address at that point in the VTABLE, but in either case, making a
virtual call to that VTABLE address is not what you want to do. So the compiler
is doing its job by protecting you from making virtual calls to functions that
exist only in derived classes.
There are some less-common cases in which
you may know that the pointer actually points to an object of a specific
subclass. If you want to call a function that only exists in that subclass, then
you must cast the pointer. You can remove the error message produced by the
previous program like this:
((Dog*)p[1])->sit()
Here, you happen to know that p[1]
points to a Dog object, but in general you don’t know that. If your
problem is set up so that you must know the exact types of all objects, you
should rethink it, because you’re probably not using virtual functions
properly. However, there are some situations in which the design works best (or
you have no choice) if you know the exact type of all objects kept in a generic
container. This is the problem of run-time type identification
(RTTI).
RTTI is all about casting base-class
pointers down to derived-class pointers (“up” and
“down” are relative to a typical class diagram, with the base class
at the top). Casting up happens automatically, with no coercion, because
it’s completely safe. Casting down is unsafe because there’s
no compile time information about the actual types, so you must know exactly
what type the object is. If you cast it into the wrong type, you’ll be in
trouble.
RTTI is described later in this chapter,
and Volume 2 of this book has a chapter devoted to the
subject.
Object slicing
There is a distinct difference between
passing the addresses of objects and passing objects by value when using
polymorphism. All the examples you’ve seen here, and virtually all the
examples you should see, pass addresses and not values. This is because
addresses all have the same
size[58], so
passing the address of an object of a derived type (which is usually a bigger
object) is the same as passing the address of an object of the base type (which
is usually a smaller object). As explained before, this is the goal when using
polymorphism – code that manipulates a base type can transparently
manipulate derived-type objects as well.
If you upcast to an object instead of a
pointer or reference, something will happen that may surprise you: the object is
“sliced” until all that remains is the subobject that corresponds to
the destination type of your cast. In the following example you can see what
happens when an object is sliced:
//: C15:ObjectSlicing.cpp
#include <iostream>
#include <string>
using namespace std;
class Pet {
string pname;
public:
Pet(const string& name) : pname(name) {}
virtual string name() const { return pname; }
virtual string description() const {
return "This is " + pname;
}
};
class Dog : public Pet {
string favoriteActivity;
public:
Dog(const string& name, const string& activity)
: Pet(name), favoriteActivity(activity) {}
string description() const {
return Pet::name() + " likes to " +
favoriteActivity;
}
};
void describe(Pet p) { // Slices the object
cout << p.description() << endl;
}
int main() {
Pet p("Alfred");
Dog d("Fluffy", "sleep");
describe(p);
describe(d);
} ///:~
The function describe( ) is
passed an object of type Pet by value. It then calls the virtual
function description( ) for the Pet object. In
main( ), you might expect the first call to produce “This is
Alfred,” and the second to produce “Fluffy likes to sleep.” In
fact, both calls use the base-class version of
description( ).
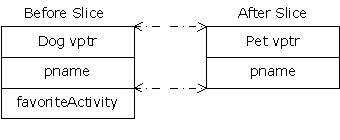
Two things are happening in this program.
First, because describe( ) accepts a Pet object
(rather than a pointer or reference), any calls to describe( ) will
cause an object the size of Pet to be pushed on the stack and cleaned up
after the call. This means that if an object of a class inherited from
Pet is passed to describe( ), the compiler accepts it, but it
copies only the Pet portion of the object. It slices the derived
portion off of the object, like this:
Now you may wonder about the virtual
function call. Dog::description( ) makes use of portions of both
Pet (which still exists) and Dog, which no longer exists because
it was sliced off! So what happens when the virtual function is
called?
You’re saved from disaster because
the object is being passed by value. Because of this, the compiler knows the
precise type of the object because the derived object has been forced to become
a base object. When passing by value, the
copy-constructor for a Pet
object is used, which initializes the VPTR to the Pet VTABLE and
copies only the Pet parts of the object. There’s no explicit
copy-constructor here, so the compiler synthesizes one. Under all
interpretations, the object truly becomes a Pet during
slicing.
Object slicing actually removes part of
the existing object as it copies it into the new object, rather than simply
changing the meaning of an address as when using a pointer or reference. Because
of this, upcasting into an object is not done often; in fact, it’s usually
something to watch out for and prevent. Note that, in this example, if
description( ) were made into a pure virtual function in the base
class (which is not unreasonable, since it doesn’t really do anything in
the base class), then the compiler would prevent object slicing because that
wouldn’t allow you to “create” an object of the base type
(which is what happens when you upcast by value). This could be the most
important value of pure virtual functions: to prevent object slicing by
generating a compile-time error message if someone tries to do
it.
Overloading &
overriding
In Chapter 14, you saw that redefining an
overloaded function in the base class
hides all of the other
base-class versions of that function. When virtual functions are involved
the behavior is a little different. Consider a modified version of the
NameHiding.cpp example from Chapter 14:
//: C15:NameHiding2.cpp
// Virtual functions restrict overloading
#include <iostream>
#include <string>
using namespace std;
class Base {
public:
virtual int f() const {
cout << "Base::f()\n";
return 1;
}
virtual void f(string) const {}
virtual void g() const {}
};
class Derived1 : public Base {
public:
void g() const {}
};
class Derived2 : public Base {
public:
// Overriding a virtual function:
int f() const {
cout << "Derived2::f()\n";
return 2;
}
};
class Derived3 : public Base {
public:
// Cannot change return type:
//! void f() const{ cout << "Derived3::f()\n";}
};
class Derived4 : public Base {
public:
// Change argument list:
int f(int) const {
cout << "Derived4::f()\n";
return 4;
}
};
int main() {
string s("hello");
Derived1 d1;
int x = d1.f();
d1.f(s);
Derived2 d2;
x = d2.f();
//! d2.f(s); // string version hidden
Derived4 d4;
x = d4.f(1);
//! x = d4.f(); // f() version hidden
//! d4.f(s); // string version hidden
Base& br = d4; // Upcast
//! br.f(1); // Derived version unavailable
br.f(); // Base version available
br.f(s); // Base version abailable
} ///:~
The first thing to notice is that in
Derived3, the compiler will not allow you to change the return type of an
overridden function (it will allow it if f( ) is not virtual). This
is an important restriction because the compiler must guarantee that you can
polymorphically call the function through the base class, and if the base class
is expecting an int to be returned from f( ), then the
derived-class version of f( ) must keep that contract or else things
will break.
The rule shown in Chapter 14 still works:
if you override one of the overloaded member functions in the base class, the
other overloaded versions become hidden in the derived class. In main( )
the code that tests Derived4 shows that this happens even if the new
version of f( ) isn’t actually overriding an existing virtual
function interface – both of the base-class versions of f( )
are hidden by f(int). However, if you upcast d4 to Base,
then only the base-class versions are available (because that’s what the
base-class contract promises) and the derived-class version is not available
(because it isn’t specified in the base
class).
Variant return type
The Derived3 class above suggests
that you cannot modify the return type of a virtual function during overriding.
This is generally true, but there is a special case in which you can slightly
modify the return type. If you’re returning a pointer or a reference to a
base class, then the overridden version of the function may return a pointer or
reference to a class derived from what the base returns. For
example:
//: C15:VariantReturn.cpp
// Returning a pointer or reference to a derived
// type during ovverriding
#include <iostream>
#include <string>
using namespace std;
class PetFood {
public:
virtual string foodType() const = 0;
};
class Pet {
public:
virtual string type() const = 0;
virtual PetFood* eats() = 0;
};
class Bird : public Pet {
public:
string type() const { return "Bird"; }
class BirdFood : public PetFood {
public:
string foodType() const {
return "Bird food";
}
};
// Upcast to base type:
PetFood* eats() { return &bf; }
private:
BirdFood bf;
};
class Cat : public Pet {
public:
string type() const { return "Cat"; }
class CatFood : public PetFood {
public:
string foodType() const { return "Birds"; }
};
// Return exact type instead:
CatFood* eats() { return &cf; }
private:
CatFood cf;
};
int main() {
Bird b;
Cat c;
Pet* p[] = { &b, &c, };
for(int i = 0; i < sizeof p / sizeof *p; i++)
cout << p[i]->type() << " eats "
<< p[i]->eats()->foodType() << endl;
// Can return the exact type:
Cat::CatFood* cf = c.eats();
Bird::BirdFood* bf;
// Cannot return the exact type:
//! bf = b.eats();
// Must downcast:
bf = dynamic_cast<Bird::BirdFood*>(b.eats());
} ///:~
The Pet::eats( ) member
function returns a pointer to a PetFood. In Bird, this member
function is overloaded exactly as in the base class, including the return type.
That is, Bird::eats( ) upcasts the BirdFood to a
PetFood.
But in Cat, the return type of
eats( ) is a pointer to CatFood, a type derived from
PetFood. The fact that the return type is inherited from the return type
of the base-class function is the only reason this compiles. That way, the
contract is still fulfilled; eats( ) always returns a PetFood
pointer.
If you think polymorphically, this
doesn’t seem necessary. Why not just upcast all the return types to
PetFood*, just as Bird::eats( ) did? This is typically a good
solution, but at the end of main( ), you see the difference:
Cat::eats( ) can return the exact type of PetFood, whereas
the return value of Bird::eats( ) must be downcast to the exact
type.
So being able to return the exact type is
a little more general, and doesn’t lose the specific type information by
automatically upcasting. However, returning the base type will generally solve
your problems so this is a rather specialized
feature.
 |
|
|